
rm(X;Y)
Returns a boolean value indicating whether a given string matches a standard regular expression. (Available as of version 12.33)
Syntax
rm(X;Y)Input
| Argument | Type | Description |
|---|---|---|
X |
text | The string on which to apply the function A scalar value or the name of a column |
Y |
text | A regular expression with which to compare string X. |
Return Value
Returns an integer value of 1 if X matches the regular expression
Y. Otherwise, returns 0.
If X is N/A, the result is 0.
Sample Usage
value |
regular expression |
rm(value;regular expression) |
|---|---|---|
| 'abcdefg' | 'a(b|c|d)' | 1 |
| 'abcdefg' | 'A(b|c|d)' | 0 |
| 'aefg' | 'a(b|c|d)' | 0 |
Example
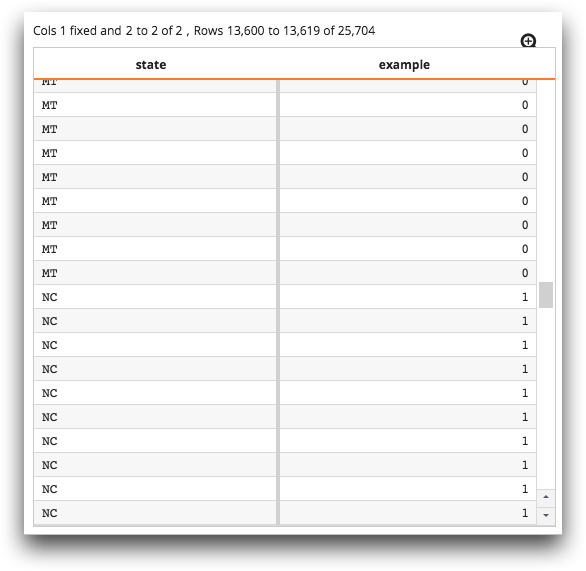
In the "Monthly Statewide Seasonally Adjusted Unemployment Statistics" table
(pub.fin.fred2.bls.smsa), you can find only those rows whose state
abbreviations begin with the letter "N". To do this, create a
computed column and apply the rm(X;Y) function to the
state column, and specify "N?" as the pattern to
match.
<base table="pub.fin.fred2.bls.smsa"/> <willbe name="example" value="rm(state;'N?')" label="States Beginning`With N"/> <colord cols="state,example"/>
For those values in the state column that begin with "N",
the result is 1. Otherwise, the result is
0.
Additional Information
rm(X;Y)is similar tosm(X;Y), except that in this function,Yis a regular expression, not a wildcard-containing pattern.rm(X;Y)is equivalent toregex_count(Y;'pcre''first';X)>0.- This function does not work with Unicode (UTF-8) strings.
- For a Unicode-compliant alternative, consider
regex_match(X;L;Y;I).