
taketo(X;Y)
Returns the beginning part of a given string up to but excluding the first occurrence of a particular substring.
Syntax
taketo(X;Y)Input
| Argument | Type | Description |
|---|---|---|
X |
text | The string on which to apply the function A column name |
Y |
text | A substring in X that defines the point before which the
resultant string begins |
Return Value
Returns the text string from the beginning of X up to but excluding the
first occurrence of the string Y.
If X is N/A, the result is N/A. If there is no occurrence of
Y in X, the result is the value of
X.
Sample Usage
value |
instance |
taketo(value;instance) |
|---|---|---|
| 'ana@aol.com' | '@' | 'ana' |
Example
In the "ZIP to CBSA Mapping" table (pub.geo.cbsa), the values in the
cbsa_name column consist of strings of the form
"city, state". You can take the
text up to but excluding the ", " to obtain just the name of the
city. To do this, create a computed column and apply
the taketo(X;Y) function to the cbsa_name column,
specifying the string ", " as the Y parameter.
<base table="pub.geo.cbsa"/> <willbe name="example" value="taketo(cbsa_name;', ')"/> <colord cols="cbsa_name,example"/>
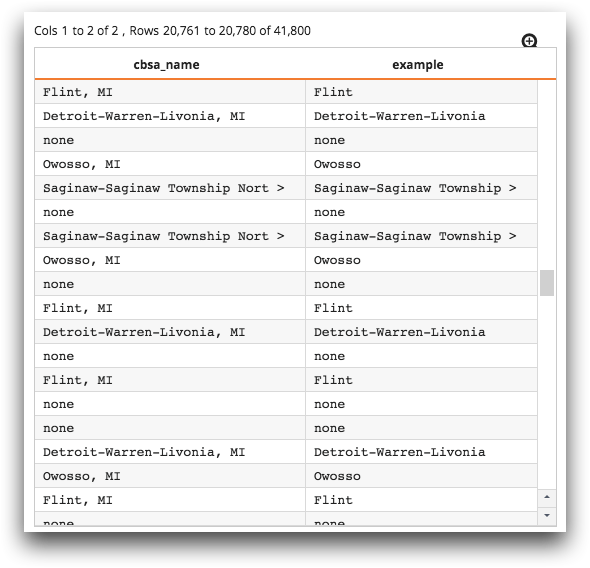
For those values that do not have this "city,
state" structure, the value of X is
returned.
Additional Information
- This function does not work with Unicode (UTF-8) strings.
- For Unicode-compliant alternatives, consider:
strfind(X;Y;I)strextract(X;P;N)