
Finding duplicates
Sometimes tables contain duplicate entries and it can be necessary to locate and remove these duplicates.
Difficulty

Objective
You merged two tables containing similar information, but now there appears to be duplicates in your new table. You would like to locate and remove these duplicates. You know how to do this in Excel by utilizing the Remove Duplicates dialog, and you would like to perform the same operations using 1010data.
Excel solution
Excel has multiple ways to locate and remove duplicates. One way is to use the Remove Duplicates dialog, located on the Data tab in the Data Tools group. Using the Remove Duplicates dialog, you can determine the duplicates in your table using multiple criteria. For this analogue, duplicates in the table are determined if they share the same county name, state name and 50 percentile 0 bedroom rent. The image below shows the dialog in Excel with these columns selected.
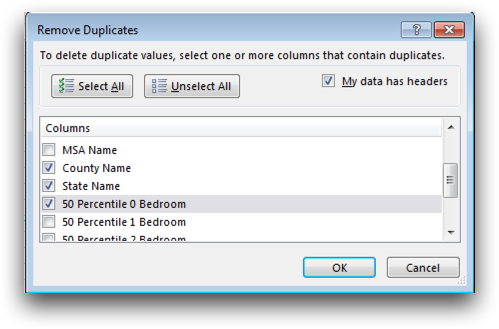
Upon selecting OK, all duplicates will be removed and you will be left with the following table.
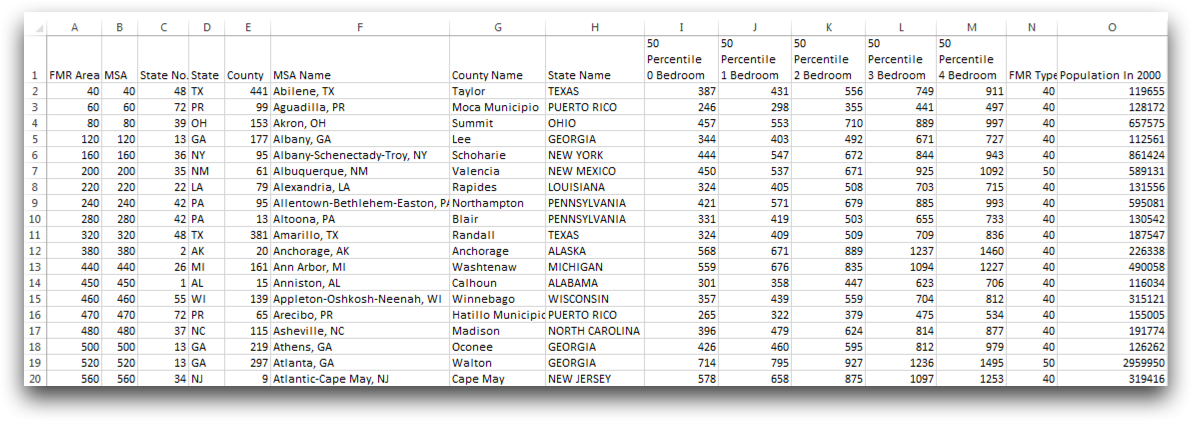
Although Excel offers a simple tool to remove duplicates, 1010data can process more data at a faster speed with similar ease.
1010data Macro Language solution
<base table="pub.doc.gov.area.x2003"/> <merge table2="pub.doc.gov.county.x2003"/> <tabu label="Tabulation on Worksheet" breaks="countyname,statename,rent50_0"> <tcol source="rent50_0" fun="first" label="First Rent"/> </tabu> <link table2="pub.doc.gov.area.x2003" col="countyname,statename,rent50_0" col2="countyname,statename,rent50_0" type="select"> <merge table2="pub.doc.gov.county.x2003"/> </link>
When finding duplicates, you need to establish the columns that uniquely identify each row.
For example, a table containing sales information could have rows that can be uniquely
identified by the transaction ID and the item SKU. In this recipe, rows are uniquely
identified by the columns msa, countyname, and
rent50_0.
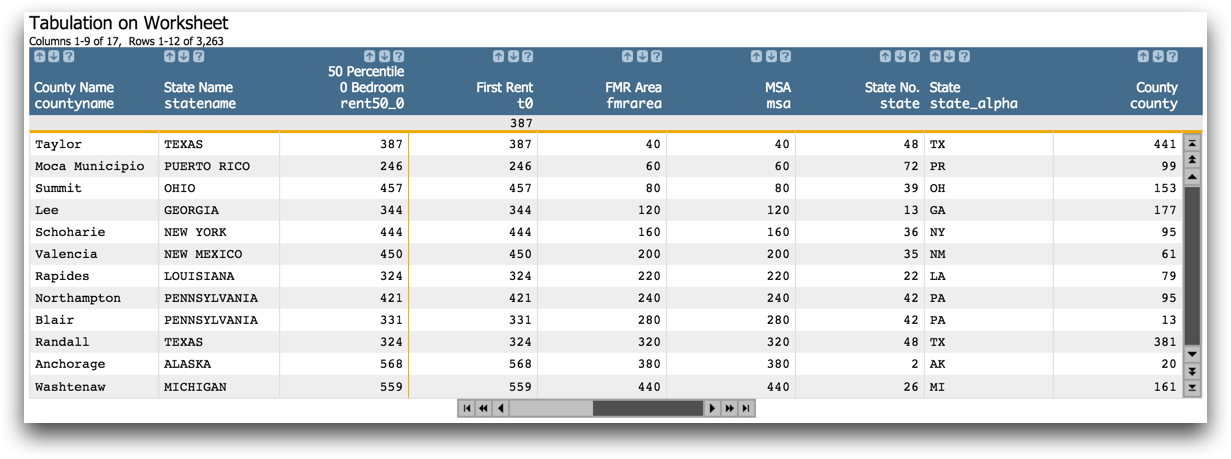
This solution uses a tabulation where the aforementioned columns are used for grouping and the first entry in each group is selected. Then the original merged worksheet is linked in and all of the duplicate rows are no longer present, as can be seen below.
Alternate 1010data Macro Language solution
<base table="pub.doc.gov.area.x2003"/> <merge table2="pub.doc.gov.county.x2003"/> <willbe name="test" value="g_cnt(countyname statename rent50_0;)>1"/> <sel value="g_first1(countyname statename rent50_0;;)"/>
Alternatively, you can use g_cnt(G;S) to discover if there are any
duplicates present in the table using the unique identifiers described in the previous
solution, and then use g_first1(G;S;O) to select only the first instance.
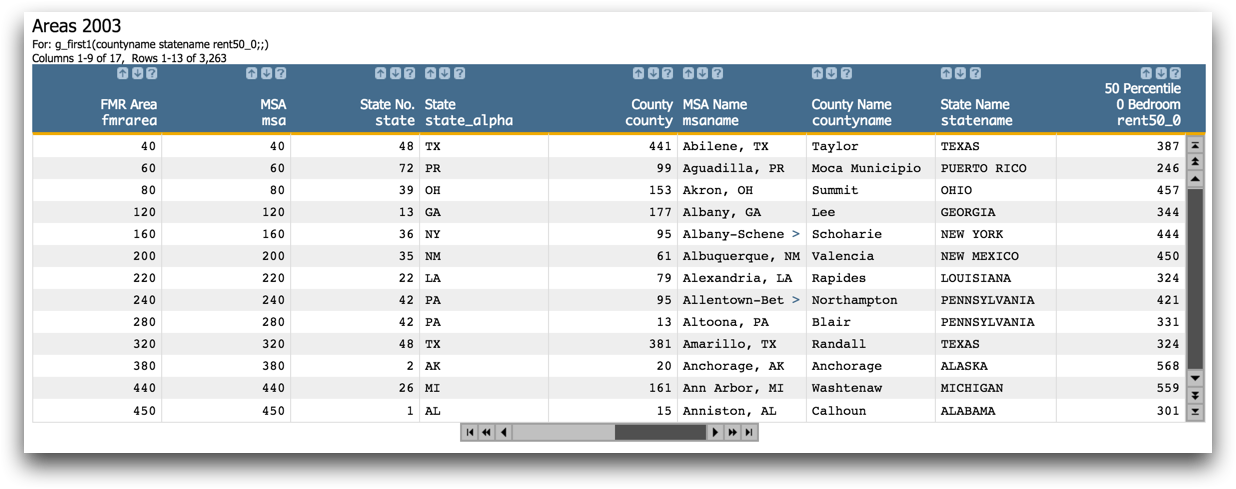
This method is particularly useful if your table is segmented. The final table without
duplicates can be seen below.
Further reading
If you would like to learn more about the functions and operations discussed in this recipe, click on the links below: