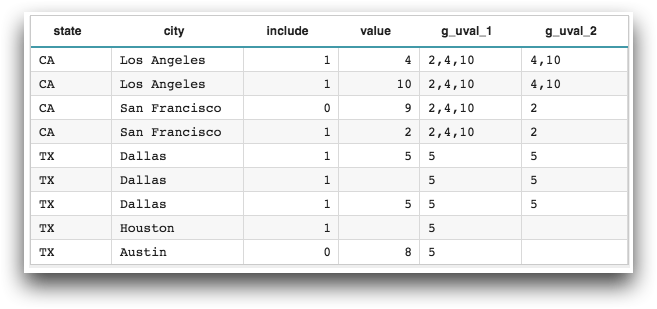
g_uval(G;S;X;D;N)
Returns a concatenated list of distinct values within a given group.
Function type
Vector only
Syntax
g_uval(G;S;X;D;N)Input
| Argument | Type | Description |
|---|---|---|
G |
any | A space- or comma-separated list of column names Rows are in the same group
if their values for all of the columns listed in If If any of the columns listed in |
S |
integer | The name of a column in which every row evaluates to a 1 or 0, which determines
whether or not that row is selected to be included in the calculation If
If any of the values in
|
X |
any simple type | The column on which to apply the function A column name N/As
in |
D |
text | A single character used to separate the distinct values Note: The character should be surrounded by single quotes.
If |
N |
integer | The maximum number of distinct values in the result If the total number of distinct values exceeds this value, the result is truncated. If
|
Return Value
For every row in each group defined by G (and for those rows where
S=1, if specified), g_uval
returns a text value corresponding to the concatenation of the distinct values of
X in all rows that are in the same group as that row. The values are
presented in alphabetical order and are separated by the character denoted by
D.
If all values for a particular group are N/A, the result is the empty string.
Sample Usage
<base table="pub.doc.samples.ref.func.g_func_sample_usage"/> <willbe name="g_uval_1" value="g_uval(state;include;value;',';20)"/> <willbe name="g_uval_2" value="g_uval(state city;include;value;',';20)"/>
Example
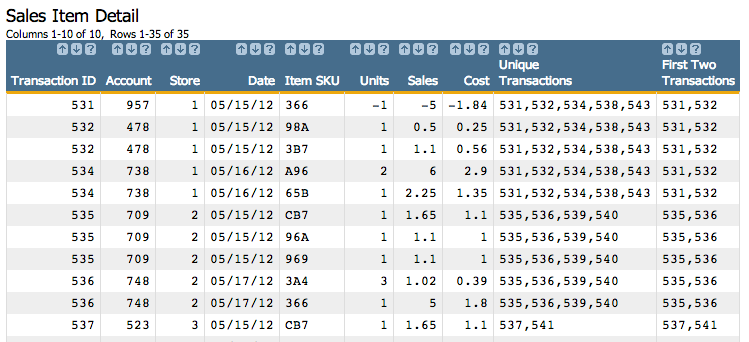
Let's say we want to list the unique transactions that occurred at every store in our Sales Item Detail table (pub.demo.retail.item).
<base table="pub.demo.retail.item"/>Create a computed column using the g_uval(G;S;X;D;N) function. Specify
store as the group (G), since we're grouping by store;
specify transid as X since we want the list of unique
transactions; and leave the selection parameter (S) blank, since we want to
take into account all of the transactions (not just a subset of those transactions). Also,
specify a comma as the separator (D) and set the maximum number of unique
values to 20 (N).
<willbe name="uniquetrans" value="g_uval(store;;transid;',';20)" label="Unique`Transactions"/>The results from this will look like the following:
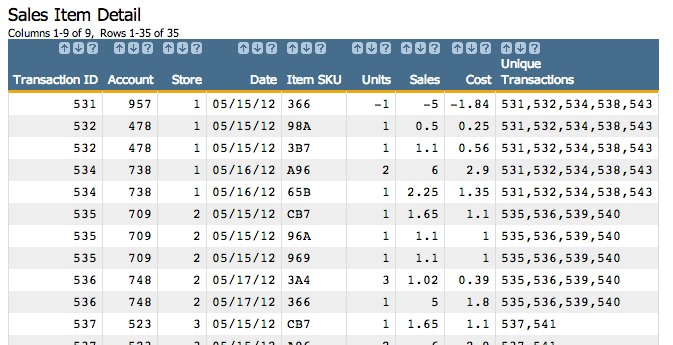
If we wanted to limit the number of unique transactions to just the first two, we could
change the N parameter to 2:
<willbe name="firsttwo" value="g_uval(store;;transid;',';2)" label="First Two`Transactions"/>This would result in something that looks like the following: