
g_splice(G;S;O;X;D;N)
Returns a concatenated list of values ordered in a specified manner within a given group.
Function type
Vector only
Syntax
g_splice(G;S;O;X;D;N)Input
| Argument | Type | Description |
|---|---|---|
G |
any | A space- or comma-separated list of column names Rows are in the same group
if their values for all of the columns listed in If If any of the columns listed in |
S |
integer | The name of a column in which every row evaluates to a 1 or 0, which determines
whether or not that row is selected to be included in the calculation If
If any of the values in
|
O |
integer | A space- or comma-separated list of column names that
determine the row order within a particular group If
Rows that have N/A values in |
X |
any | The column on which to apply the function A column name |
D |
text | A string used to separate the values Note: The string should be surrounded by single quotes.
If |
N |
integer | The maximum number of values in the result If the total number of values exceeds this value, the result is truncated. If |
Return Value
For every row in each group defined by G (and for those rows where
S=1, if specified), g_splice
returns a text value corresponding to the concatenation of all of the values of
X in all rows that are in the same group as that row. The order of the
values is determined by the values in O; if O is omitted,
the values are presented in the order they appear in the table. The values are separated by
the string specified by D.
Sample Usage
<base table="pub.doc.samples.ref.func.g_func_time_series_sample_usage"/> <willbe name="g_splice_1" value="g_splice(state;include;order;value;',';20)"/> <willbe name="g_splice_2" value="g_splice(state city;include;order;value;',';20)"/>
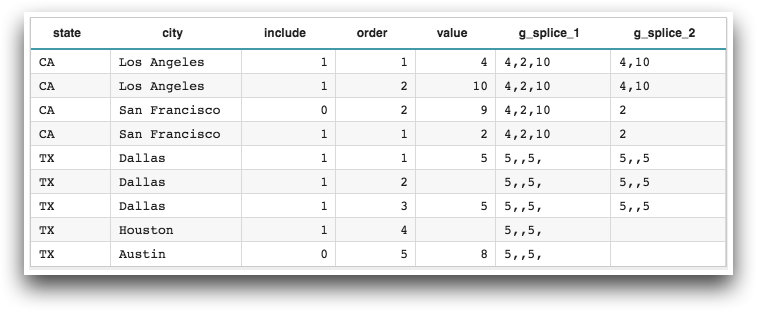
Example
Let's say we want a list of all the SKUs for each department that is in our Product Master table (pub.demo.retail.prod).
Create a computed column using the g_splice(G;S;O;X;D;N) function. Specify
dept as the group (G), since we're grouping by
department; specify sku as X since we want the list of
SKUs; and leave the selection parameter (S) blank, since we want to take
into account all of the SKUs in the table (not just a subset). For demonstration purposes,
we'll order the SKUs by class by specifying class for the
O parameter. We'll use a comma as the separator (D) and
set the maximum number of values to 20 (N).
<base table="pub.demo.retail.prod"/> <willbe name="skus_by_dept" value="g_splice(dept;;class;sku;',';20)" label="SKUs by Dept"/>
The results from this will look like the following:
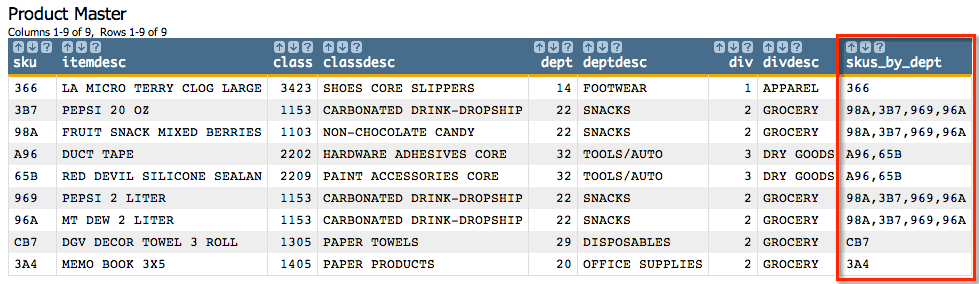
You can see from the example that the only SKU in department 14 is
366. In department 22, there are four SKUs appearing in the
table in the following order: 3B7, 98A,
969, and 96A; however, since we specified
them to be ordered by the value in the class column,
g_splice orders them as 98A,
3B7, 969, and
96A, separated by commas.