
g_asof(G;S;O;X;Y;TX;TY;BA;L)
Returns the position of the row within a given group where all the values in one or more columns most closely match the values in another specified set of columns.
Function type
Vector only
Syntax
g_asof(G;S;O;X;Y;TX;TY;BA;L)
t_asof(X;Y;TX;TY;BA;L)Input
| Argument | Type | Description |
|---|---|---|
G |
any | A space- or comma-separated list of column names Rows are in the same group
if their values for all of the columns listed in If If any of the columns listed in |
S |
integer | The name of a column in which every row evaluates to a 1 or 0, which determines
whether or not that row is selected to be included in the calculation If
If any of the values in
|
O |
integer | A space- or comma-separated list of column names that
determine the row order within a particular group If
If any of the values in |
X |
any | A space- or comma-separated list of column names |
Y |
any | A space- or
comma-separated list of column names The values in the columns specified by Note: The number of the columns in
Y must be the same as those in
X, and the data types of the columns listed in
Y should also match those listed in X. |
TX |
text | A string representing the type of the time-series column in
XThe choice of Valid types are:
If |
TY |
text | A string representing the type of the time-series column in
YThe choice of Valid types are:
If |
BA |
text | Specifies, if there is no exact match, whether the values in Y
should come before or after the values in XBA can
have either of the following values:
If |
L |
integer or decimal | A whole-number value that specifies the number of rows to shift the result If
If
|
Return Value
G (and for those rows where
S=1, if specified), the values in the column(s)
specified by Y are searched for in the column(s) specified by
X:- If
BAis'after',g_asofreturns an integer value corresponding to the index of the last row inXwhose values are less than or equal toY. - If
BAis'before',g_asofreturns an integer value corresponding to the index of the first row inXwhose values are greater than or equal toY.
The order is determined by O; if O is omitted, the order
is determined by the current row order.
If there is no match, the result is N/A.
Sample Usage
<base table="pub.doc.samples.ref.func.g_asof_sample_usage"/> <willbe name="g_asof_1" value="g_asof(symbol;;;sendtime;srctime;'T';'T';'before';0)"/> <willbe name="g_asof_2" value="g_asof(symbol;;;sendtime;srctime;'T';'T';'after';0)"/> <willbe name="g_asof_3" value="g_asof(symbol;;;sendtime;srctime;'T';'T';'after';2)"/>
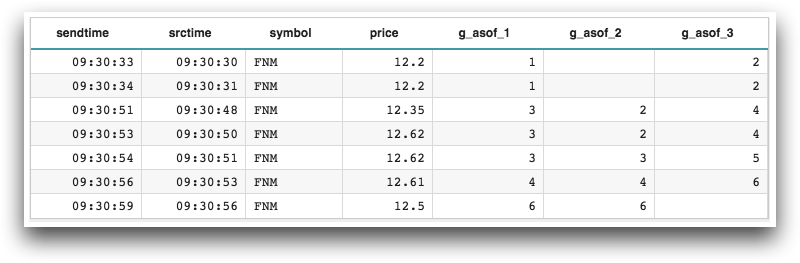
Example
Let's use the Weather Underground Observed Daily table
(pub.demo.weather.wunderground.observed_daily) to illustrate the use
of g_asof(G;S;O;X;Y;TX;TY;BA;L).
Let's say we want to find out, for each day in every zip code, the high temperature on the same day the year before. If there is no data for exactly one year before, we'll take the closest day before that.
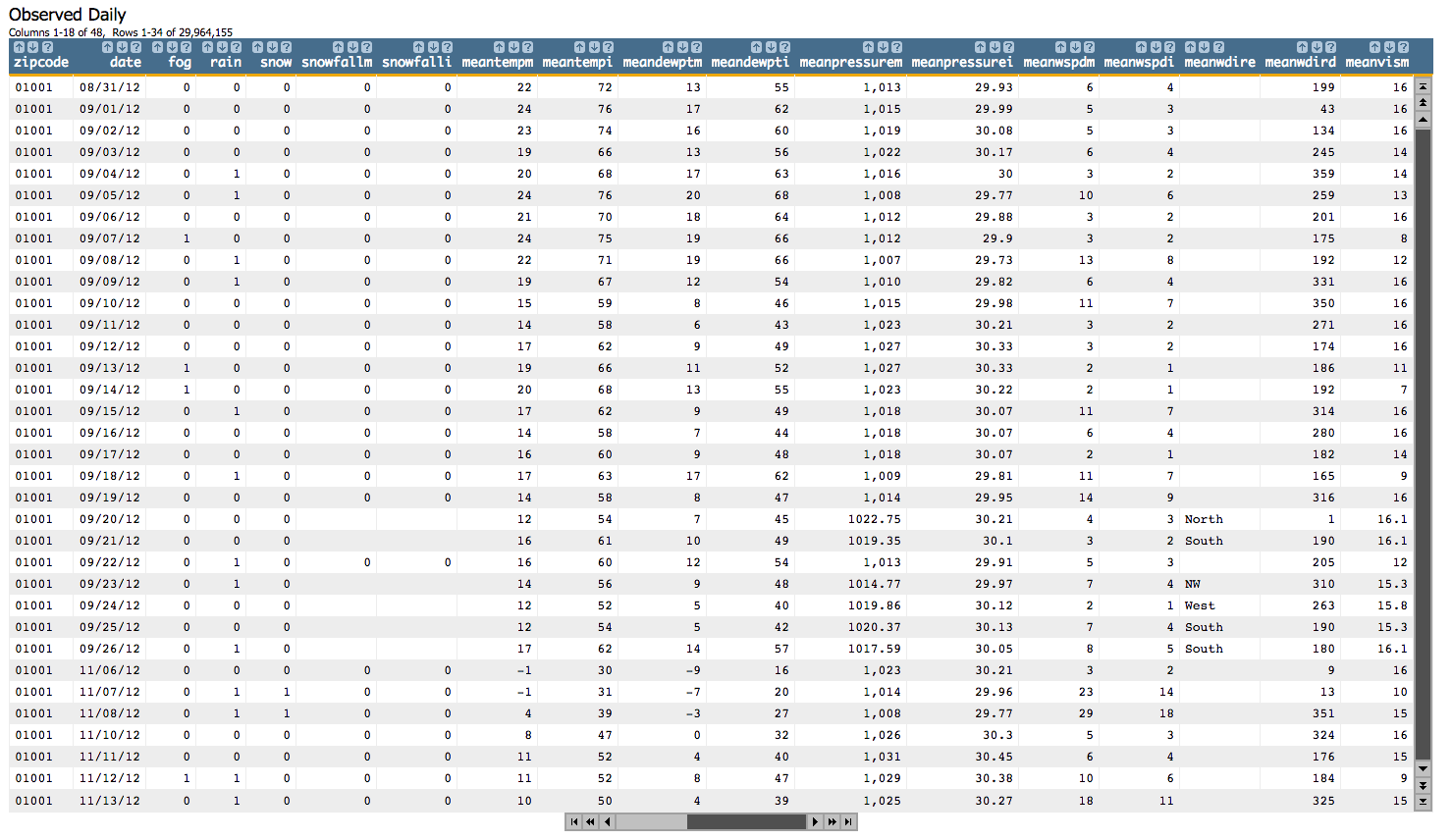
We'll start out by opening the Observed Daily table, which looks something like this:
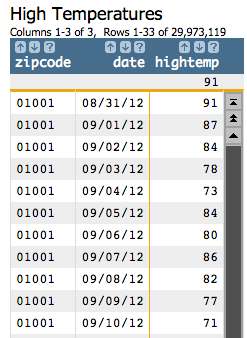
<tabu>, grouping by both zipcode and
date, and finding the high temperature
(maxtempi).<tabu label="High Temperatures" breaks="zipcode,date">
<tcol source="maxtempi" fun="first" name="hightemp" label="Highest`Max`Temp`(F)"/>
</tabu>fun="first" will give us that high temperature, though we could have
also specified last, lo, or hi for the
fun attribute to get the same results.Our table now looks similar to the following:
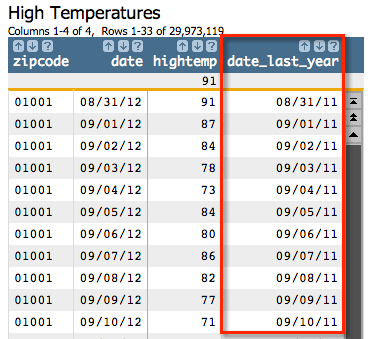
shiftmonths(X;Y;E)
function:<willbe name="date_last_year" value="shiftmonths(date;-12;0)"/>This adds the following column to our table:
Now let's use our g_asof(G;S;O;X;Y;TX;TY;BA;L) function to find the row
whose value in the date column is equal to or less than the current row's
value in the date_last_year column. Let's specify the
zipcode column for our G parameter so that we're
grouping by zip code. We'll omit the S parameter so that the function
considers all rows and not just a subset, and we'll specify the date column
for our O parameter so that the order is based on the date. Since we want
to compare the dates for the current year to the dates from a year ago, we'll specify
date for our X parameter and
date_last_year for our Y parameter. Because both of
those columns have values in the form YYYYMMDD, we'll specify
'D' for both the TX and TY parameters.
Since we want the index of the last row whose value in the date column is
equal to or less than the current row's value in the date_last_year column,
we'll specify 'after' for the BA parameter. Finally, since
we don't want to offset our results at all, we'll specify 0 for
L.
g_asof(G;S;O;X;Y;TX;TY;BA;L)
function:<willbe name="asof" value="g_asof(zipcode;;date;date;date_last_year;'D';'D';'after';0)"/>g_asof(zipcode;;date;date;date_last_year;;;;) and achieved the same
results.We should see something like the following:
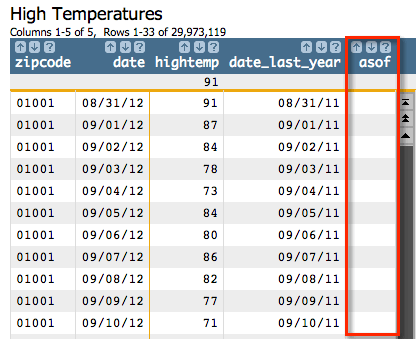
Since there is no information in our table prior to 08/31/12, we see N/A values in the new
asof column.
Click and enter "asof<>NA" in the
Expression field, then click Find Next to go
to the first row that does not contain an N/A in the asof column. You
should see something similar to the following:
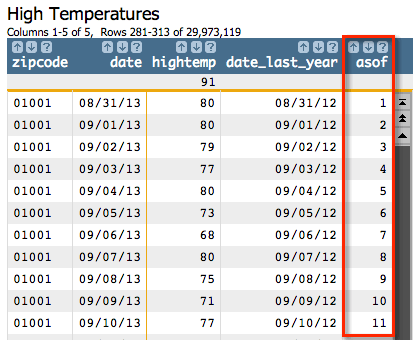
We can see that the date column in the first row has the value
08/31/13 and that the date_last_year column
is 08/31/12. We can also see that the asof
column contains the value 1, which means that the first row in
the group with the zip code 01001 has a value of 08/31/12 in its date
column.
g_pick(G;S;O;X;Y) function. Since we want
the high temperature associated with the index, we'll specify the hightemp
column for X, and we'll specify our asof index for the
Y
parameter:<willbe name="maxtemp_last_year" value="g_pick(zipcode;;date;hightemp;asof)"/>zipcode and ordering by
date.maxtemp_last_year values
from:<willbe name="maxtemp_date_last_year" value="g_pick(zipcode;;date;date;asof)"/>date for the X parameter instead of
hightemp,We should see something like the following:
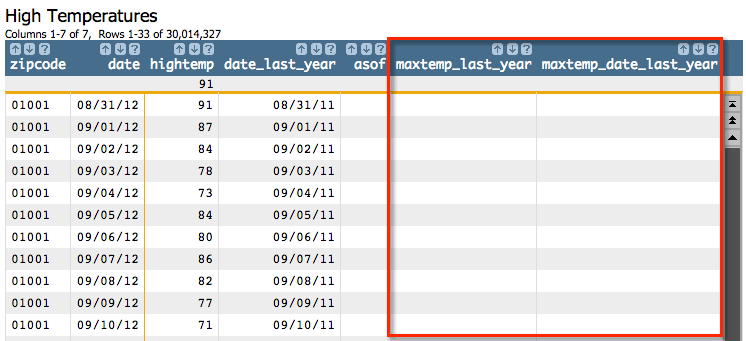
Let's go to the first row that does not have an N/A value in the
maxtemp_last_year column. You can right-click on any cell in the
maxtemp_last_year column that has an N/A value and click Find
next row where maxtemp_last_year does not have the value N/A:
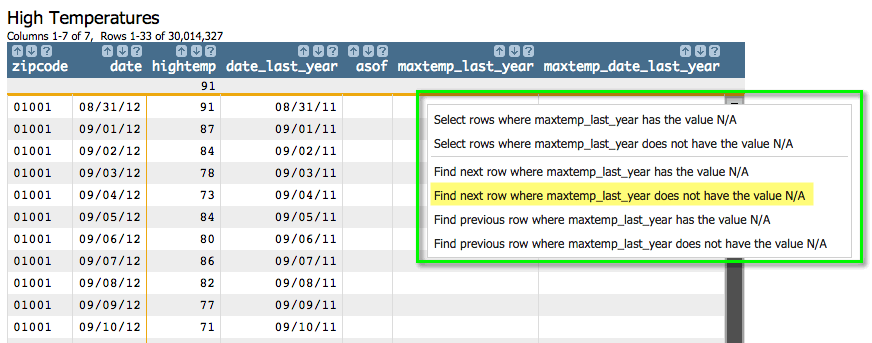
You should see something similar to the following:
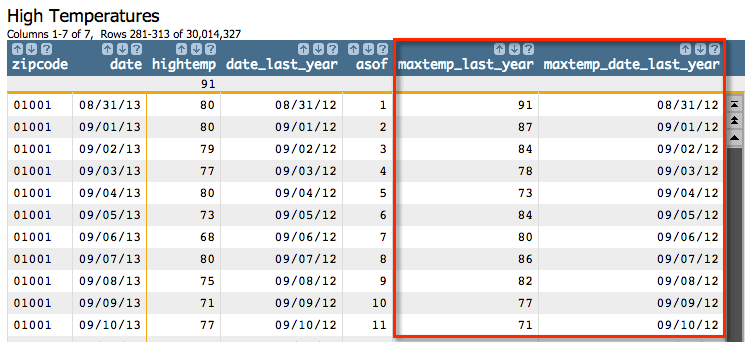
In the first row, we can see that on 08/31/13, the high temperature was 80 degrees. We
calculated that the prior year's date was 8/31/12, which makes sense. The results from
g_asof(G;S;O;X;Y;TX;TY;BA;L) for that row returned that our matching row
was row 1 in the zip code 01001 grouping. The results from
g_pick(G;S;O;X;Y) for that index returned a high temperature of 91, and
the date associated with that index was 08/31/12, which matches the date we calculated. So
it looks like our table had the information for exactly one year before the date we were
interested in.
Now let's see how g_asof(G;S;O;X;Y;TX;TY;BA;L) handles the situation if
the table didn't have information for the exact same day one year before.
For example, in this table, there is a gap in the data from 09/26/12 to 11/06/12:
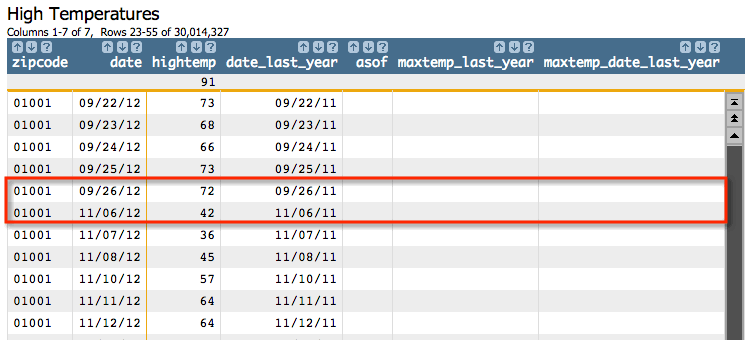
Click and enter "date_last_year<>maxtemp_date_last_year"
in the Expression field, then click Find Next
to go to the first row where the date we calculated for the year before doesn't match the
date we got from g_asof (which means that the exact date one year before
didn't exist in the table, so g_asof gave us the row with the closest date
to that). You should see something similar to the following:
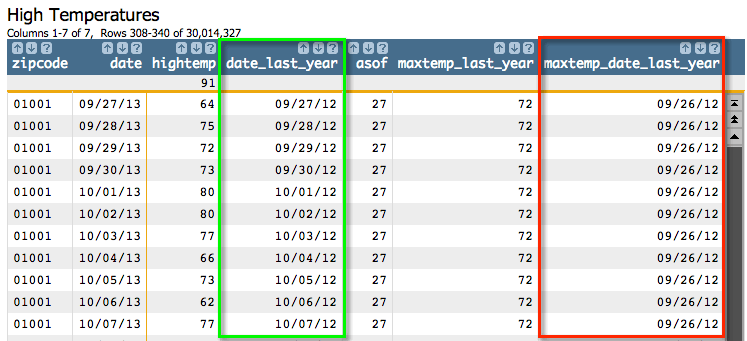
From this screenshot, we can see that on 09/27/13, the high temperature was 64 degrees. We
calculated the prior year's date as 09/27/12, which again makes sense. However,
g_asof(G;S;O;X;Y;TX;TY;BA;L) returned an index of 27, which corresponds
to the row that has the date 09/26/12, because there was no information for 09/27/12 (or, as
we can see from the screenshot, for the next number of days). So
g_asof(G;S;O;X;Y;TX;TY;BA;L) returns the information for 09/26/12, which
is the last row whose value in the date column is equal to or less than the
current row's value in the date_last_year column.
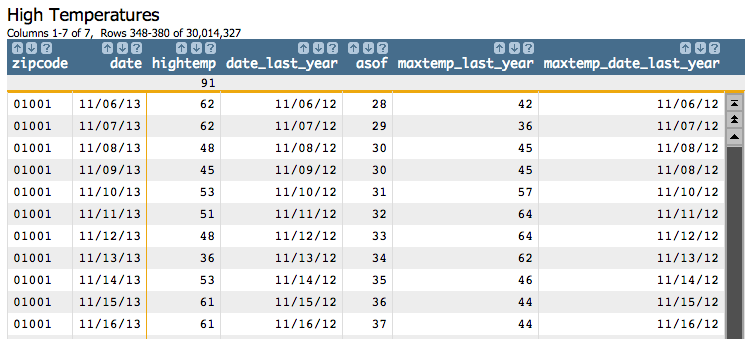
We can find the next row where date_last_year and
maxtemp_date_last_year match again by clicking and entering "date_last_year=maxtemp_date_last_year"
in the Expression field, then clicking Find
Next.
Since we have data for those dates, we see that the values in
date_last_year and maxtemp_date_last_year match, and we
can see the high temperature from those dates in the maxtemp_last_year
column.
Additional Information
- The
t_version of this function defaults theGargument and omits theSargument. The default forGis set at table load time based on the organization of the table.