
g_rankskip(G;S;X)
Returns the rank of unique values within a given group, skipping the rank after repeated values.
Function type
Vector only
Syntax
g_rankskip(G;S;X)
t_rankskip(X)Input
| Argument | Type | Description |
|---|---|---|
G |
any | A space- or comma-separated list of column names Rows are in the same group
if their values for all of the columns listed in If If any of the columns listed in |
S |
integer | The name of a column in which every row evaluates to a 1 or 0, which determines
whether or not that row is selected to be included in the calculation If
If any of the values in
|
X |
any numeric type | A column name |
Return Value
For every row in each group defined by G (and for those rows where
S=1, if specified), g_rankskip
returns an integer value corresponding to the rank of X in the list of all
valid (non-N/A) values of X within the group.
The largest value has rank 1, and subsequent (decreasing) values are ranked in increasing increments of 1 (e.g., 2, 3, 4).
Repeated values are assigned the same rank, and the value following a set of repeated values is ranked incrementally by the number of repeated values in the set.
If X is N/A, the result is N/A.
Sample Usage
<base table="pub.doc.samples.ref.func.g_func_sample_usage_two_values"/> <willbe name="g_rankskip_1" value="g_rankskip(state;include;value1)"/> <willbe name="g_rankskip_2" value="g_rankskip(state city;include;value2)"/>
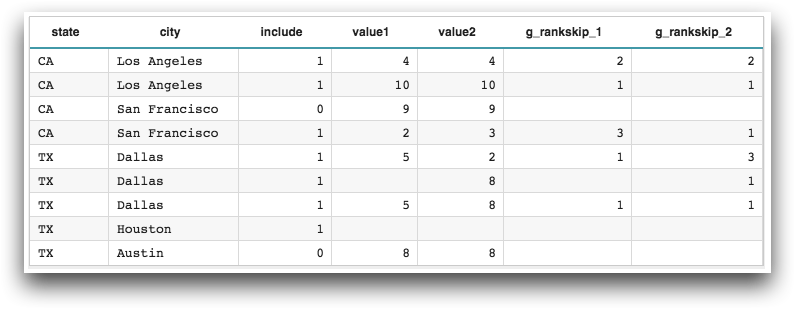
Example
Let's say we want to rank the items for all the daily transactions from highest to lowest
in terms of sales price for each store in our table, but let's say we want those items with
the same sales price to have the same rank. However, we want subsequent items to be ranked
as if the items with the sames sales price were given incremental rankings. We can easily do
this using g_rankskip(G;S;X).
Let's use the Sales Item Detail table (pub.demo.retail.item) to demonstrate the use of this function. When we open the table, it looks something like this:
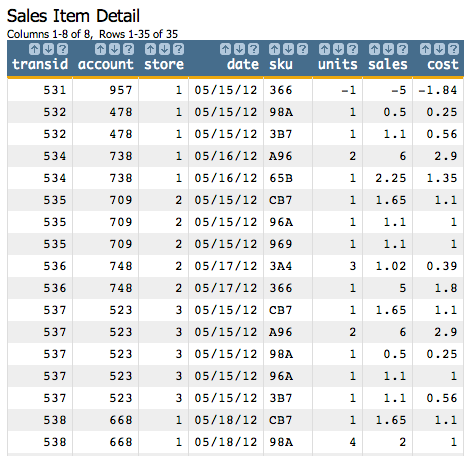
Since we want to rank the transactions for every date, and we want to do that for each
store, we'll specify the store and date columns for the
G parameter. We'll omit the S parameter so that all of
the rows will be considered, and we'll specify the sales column for
X, since we want the ranking to be based on the sales prices of the
items.
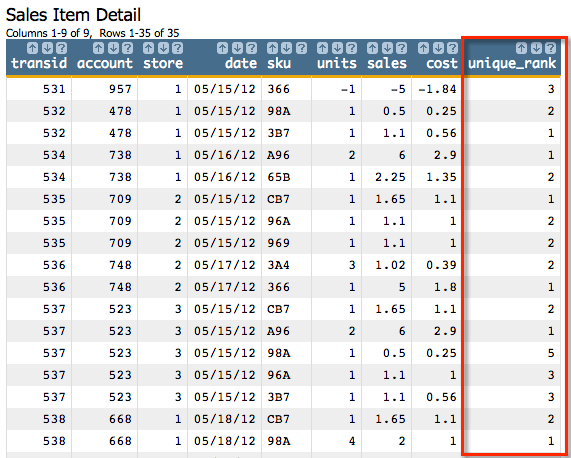
<willbe name="unique_rank" value="g_rankskip(store date;;sales)"/>This will give us a column that looks like the following:
To see the transactions in ranking order for every date for each store, you would sort first on
the rank column, then on the date
column, and then on the store column. You could do
this by clicking on the up arrow ( ) at the top of each of those columns in that order. (See Sorting rows in the 1010data User's
Guide for more information about sorting multiple columns.)
) at the top of each of those columns in that order. (See Sorting rows in the 1010data User's
Guide for more information about sorting multiple columns.)
<sort col="unique_rank" dir="up"/>
<sort col="date" dir="up"/>
<sort col="store" dir="up"/>The table would then show all the transactions for each store ordered by date, and all the transactions for each date ordered by rank:
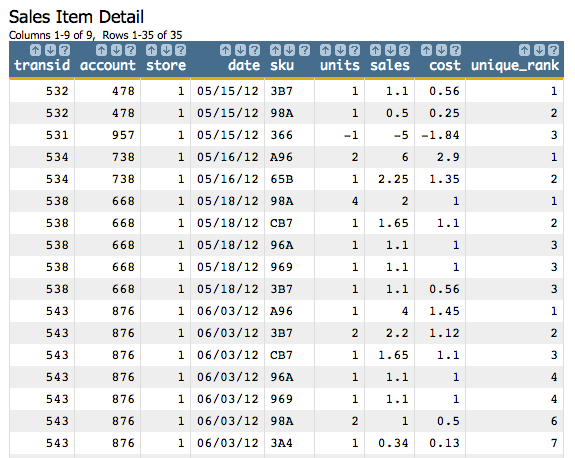
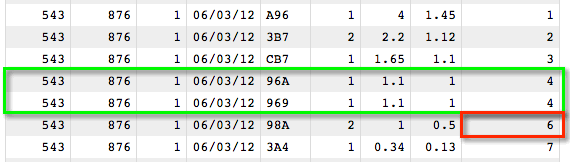
You can see that on 06/03/12, there are seven transactions that now appear in the table
ranked from the one with the highest sales to the lowest. You'll also notice that there are
two transactions with rank 4, since they have the same value in
the sales column (1.1). The next value is
given the rank 6 (taking into account the rank positions of the
previous two repeating values in the group and skipping over them).
Additional Information
- The
t_version of this function defaults theGargument and omits theSargument. The default forGis set at table load time based on the organization of the table.